collective.documentgenerator (génération de documents)#
Principe et installation#
Repository#
Principe#
Le module de génération de documents permet de créer un document bureautique, à partir d’un modèle enregistré dans le site.
La génération a lieu sur un certain contexte (un élément du site, un tableau de bord) et le document peut intégrer des données de ce contexte. Par exemple, il est possible de créer un document bureautique sur un élément Actualité de Plone et d’y reprendre l’intitulé, l’auteur, le texte, etc. Pour ce faire, le modèle de document va contenir du code informatique en plus du texte statique.
Les modèles ne sont pas disponibles pour tous les contextes. C’est dans la définition du modèle lui-même que des critères vont pouvoir restreindre l’utilisation du modèle: en fonction du type d’élément, du rôle de l’utilisateur, etc.
Il est possible de générer les documents dans plusieurs formats:
pour un document texte, le modèle doit être réalisé au format odt (format natif de LibreOffice) et il est possible de générer au format odt, doc (Word), pdf, etc.
pour un document classeur, le modèle doit être réalisé au format ods (format natif de LibreOffice) et il est possible de générer au format ods, xls (Excel), pdf, etc.
Installation et configuration#
Cette partie est donnée pour information car tout est normalement bien installé et configuré.
Installation dans Plone#
En étant connecté en tant qu’administrateur:
se rendre dans la Configuration du site, via le menu sous le nom de l’utilisateur
sélectionner ensuite Modules
les listes des modules à installer et déjà installés s’affichent
si le module collective.documentgenerator est encore dans la liste des modules disponibles, il faut cliquer sur sa case à cocher et ensuite sur le bouton Activer situé en dessous
LibreOffice#
LibreOffice doit être présent sur le même serveur que Plone afin de pouvoir effectuer différentes opérations/transformations lors de la génération.
Il doit également tourner en mode serveur pour pouvoir être utilisé par Plone.
Édition externe#
Cette fonctionnalité permet de modifier les modèles dans LibreOffice sans devoir télécharger localement le fichier, le modifier et ensuite devoir le remettre dans Plone. C’est donc plus facile et plus rapide.
Il est nécessaire pour cela d’installer l’application ZopeEdit (ainsi que le module associé dans Plone collective.externaleditor).
Configuration du module#
En étant connecté en tant qu’administrateur:
se rendre dans la Configuration du site, via le menu sous le nom de l’utilisateur
sélectionner ensuite Configuration du générateur de document
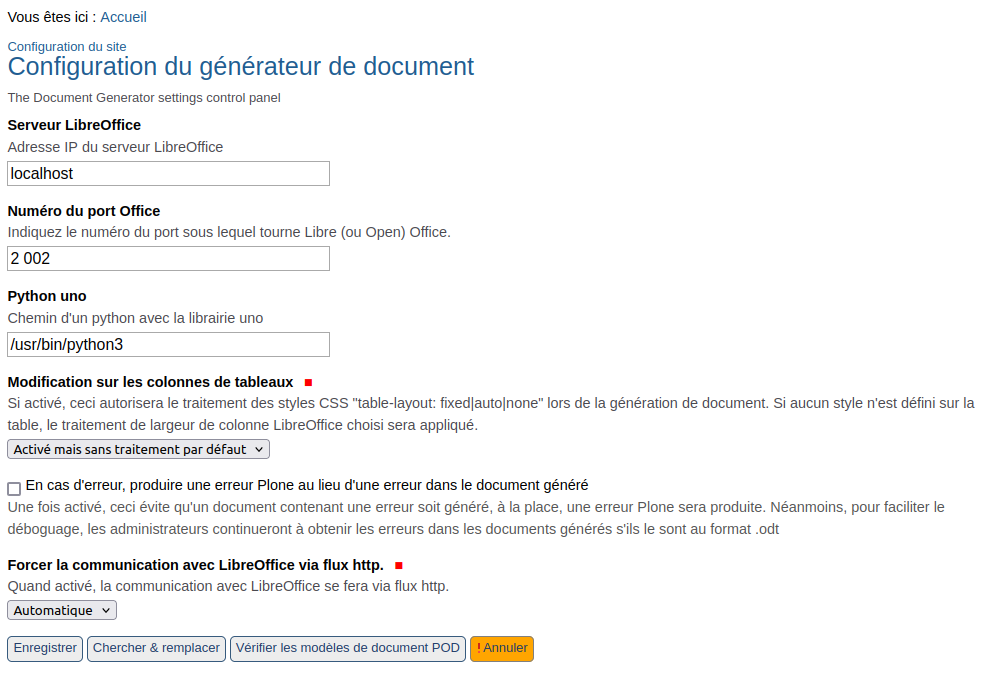
Les champs sont détaillés dans leur description associée.
Définition des modèles de document#
Où définir les modèles de document#
Pour chaque application spécifique, un ou plusieurs dossiers sont prévus pour le faire. À voir donc dans la documentation de l’application.
En dehors d’une application particulière, on peut définir les modèles dans n’importe quel dossier, mêmes différents.
Les modèles proposés à l’utilisateur sont ceux qu’il a le droit de voir. Il est donc possible d’organiser ses modèles en dossiers différents, avec chacun leur propre permission (par exemple service par service).
Types de modèles#
Il est possible de définir les types de modèle suivants:
Modèle de style: il s’agit d’un document destiné à ne contenir que la définition de styles.
Sous modèle: il s’agit d’un document contenant une partie de “texte” qui pourra être incorporée dans d’autres modèles.
Modèle de boucle de publipostage: il s’agit d’un document permettant de “boucler” sur d’autres documents.
Modèle de document POD restreint: il s’agit d’un modèle principal basique contenant juste un document.
Modèle de document POD: il s’agit d’un modèle principal contenant des paramètres supplémentaires (conditions, etc.)
Modèle de document POD pour tableau de bord: il s’agit d’un modèle principal spécifique aux tableaux de bord du produit collective.eeafaceted.dashboard.
Modèle de style#
Ce document est destiné à contenir une définition de styles, qui pourront être repris dans d’autres modèles. Seul les styles sont repris: pas du tout le contenu texte.
C’est donc un mécanisme très pratique permettant de définir ses styles à un endroit centralisé. En cas de mise à jour d’un style (comme un changement de police de caractère), le changement va se répercuter dans tous les modèles principaux qui référencent ce modèle de style.
Il est possible de définir, en plus des styles standards, de nouveaux styles (exemple: Titre pied de page). Les modèles principaux doivent utiliser les nouveaux styles avec la même dénomination. Sinon il n’y a pas de lien possible.
Si un modèle de style est modifié, après enregistrement, tous les modèles principaux qui l’utilise sont resynchronisés. Si un modèle principal est modifié, après enregistrement, il est resynchronisé par rapport au modèle de style qu’il utilise.
Lors de l’ajout ou la modification de ce type de contenu, le formulaire contient les champs suivants:
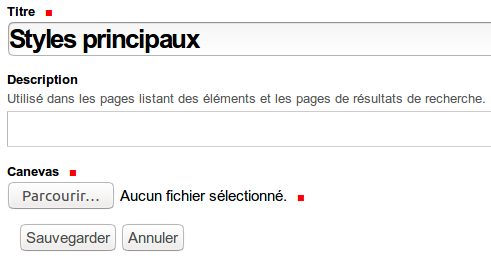
Le champ Canevas permet d’associer un document LibreOffice contenant la définition des styles.
Sous Modèle#
Ce document peut contenir un “bout” de texte mis en forme qui pourra être incorporé dans les modèles principaux.
Il s’agit donc d’un mécanisme très pratique pour définir par exemple un entête, un pied de page, une partie introduction, une partie signature, réutilisable dans beaucoup de documents mais définie à un seul endroit.
En modifiant par exemple la définition de l’entête une fois, toute génération du modèle principal qui l’utilise incorporera la nouvelle version d’entête.
Lors de l’ajout ou la modification de ce type de contenu, le formulaire contient les champs suivants:
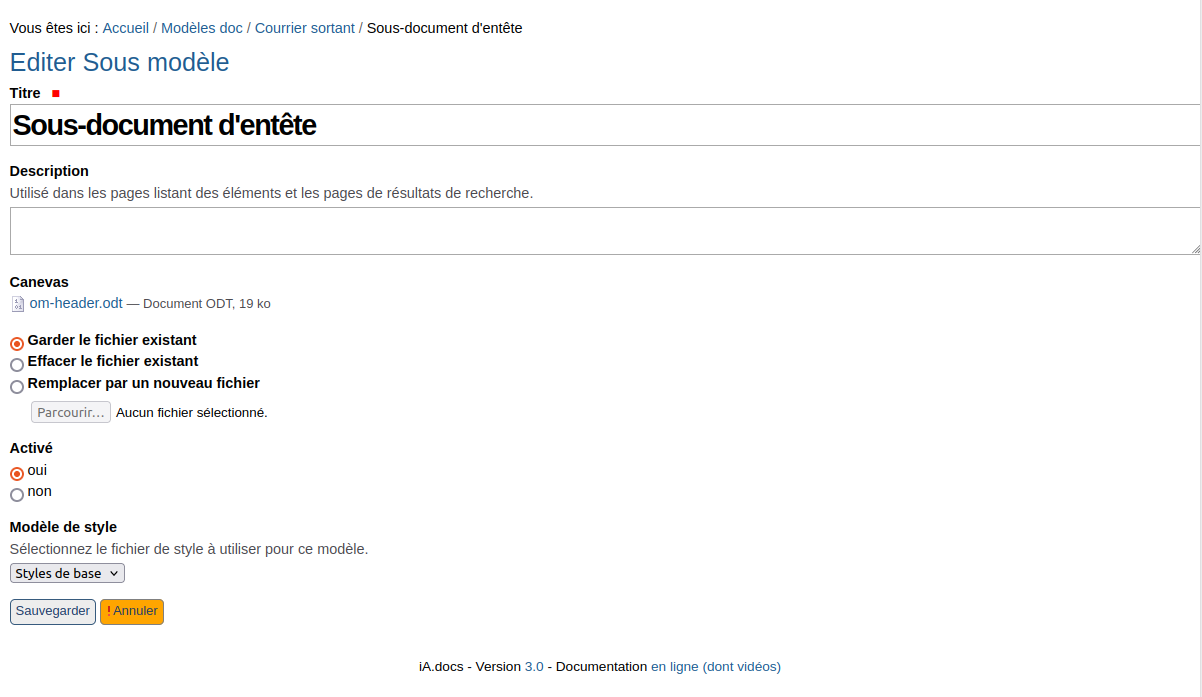
Le champ Canevas permet d’associer un document LibreOffice contenant uniquement le bout de texte qui sera “importé” ailleurs.
Le champ Activé permet de lister ou non ce sous modèle dans la liste de sélection affichée sur le modèle principal.
Le champ Modèle de style permet de sélectionner le modèle de style associé, afin de synchroniser les styles.
Modèle de boucle de publipostage#
Ce document va contenir uniquement du code informatique permettant d’incorporer un autre document répété avec des données de publipostage différentes.
Lors de l’ajout ou la modification de ce type de contenu, le formulaire contient les champs suivants:
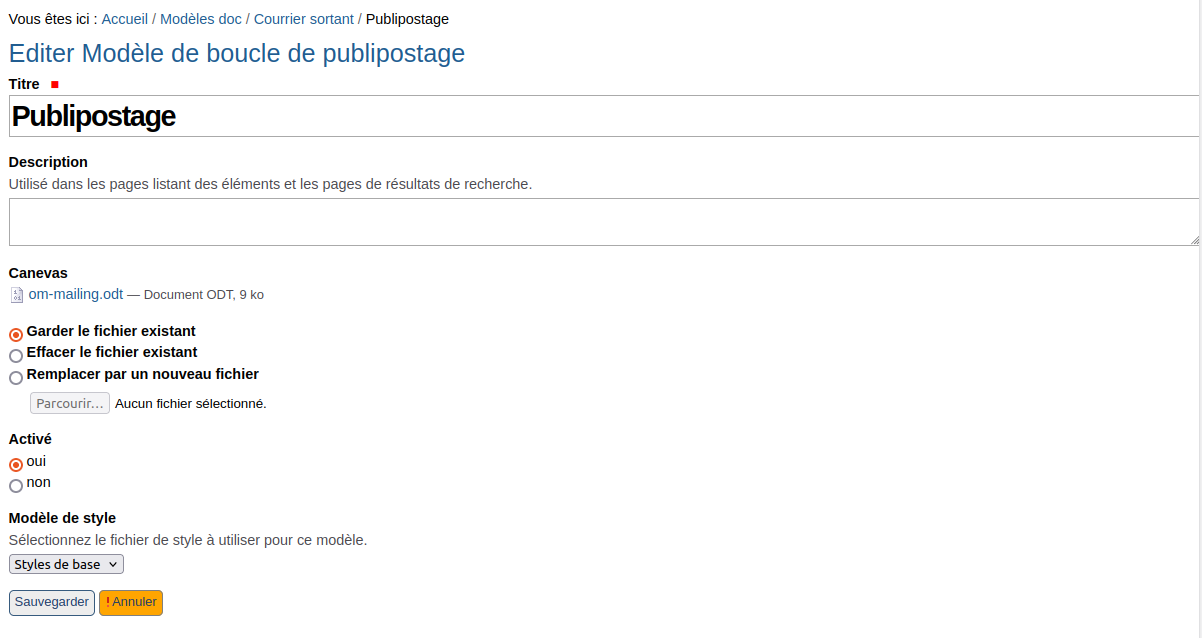
Le champ Canevas permet d’associer un document LibreOffice contenant uniquement le bout de texte qui sera “importé” ailleurs.
Le champ Activé permet de lister ou non ce sous modèle dans la liste de sélection affichée sur le modèle principal.
Le champ Modèle de style permet de sélectionner le modèle de style associé, afin de synchroniser les styles.
Modèle de document POD restreint#
Cet élément constitue un modèle principal basique qui va pouvoir être sélectionné dans l’interface utilisateur pour aboutir au document généré (qui sera au format LibreOffice).
Lors de l’ajout ou la modification de ce type de contenu, le formulaire contient les champs suivants:
Le champ Canevas permet d’associer le document LibreOffice qui va être rendu.
Le champ Modèle de style permet de sélectionner le modèle de style associé, afin de synchroniser les styles.
Modèle de document POD#
Cet élement constitue un modèle principal qui va pouvoir être sélectionné dans l’interface utilisateur pour aboutir au document généré.
Ce type de contenu, par rapport au modèle de document POD restreint, ajoute plusieurs champs complémentaires:
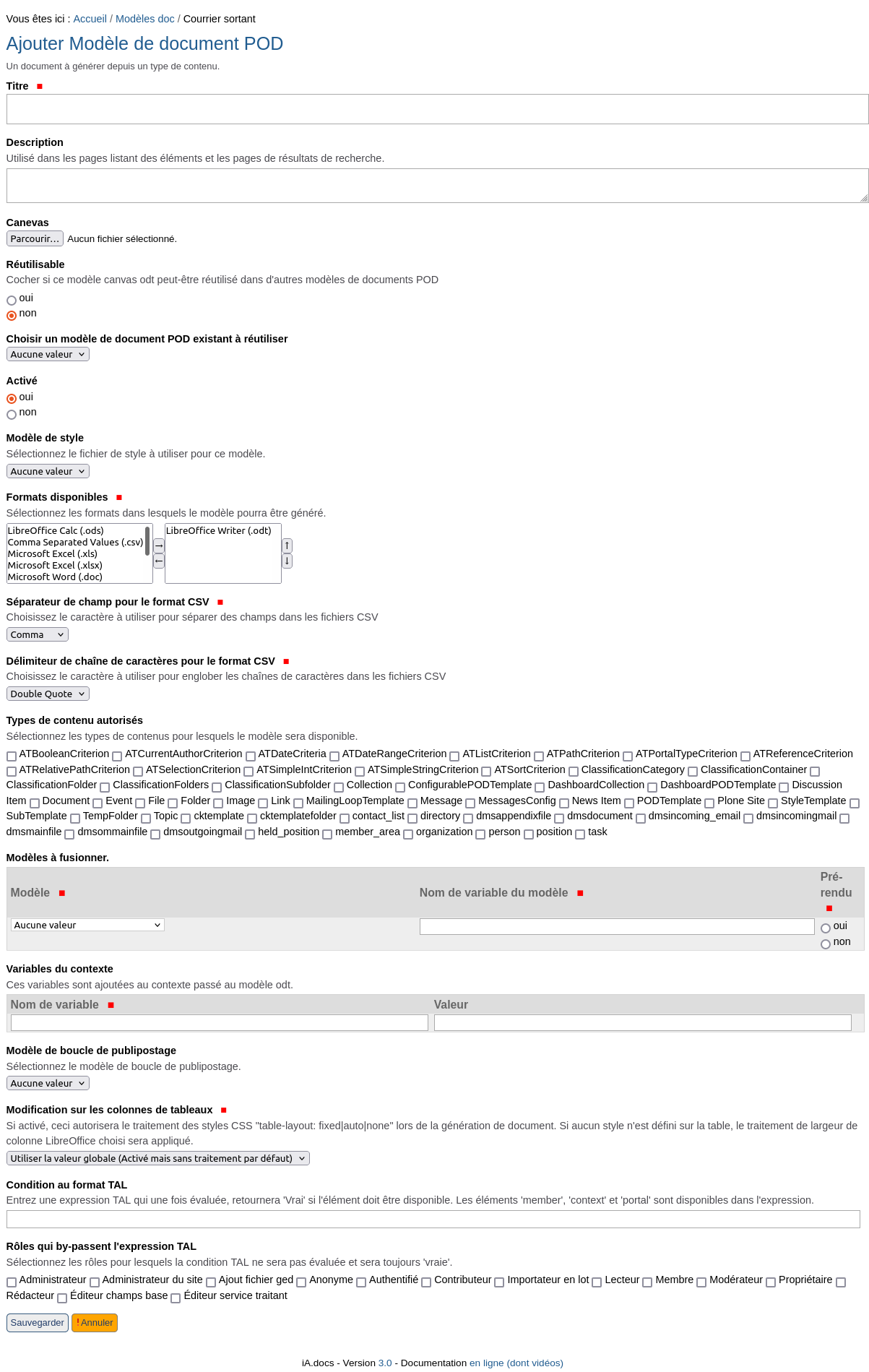
Le champ Canevas permet d’associer le document qui va être rendu.
Le champ Réutilisable permet d’indiquer si le canevas associé peut être partagé avec d’autres modèles de document (ce qui facilite la gestion des modifications).
Le champ Choisir un modèle de document POD existant à réutiliser permet de sélectionner un canevas partagé d’un autre modèle, ce qui remplace donc le choix d’un canevas propre.
Le champ Activé permet de lister ou non ce sous modèle dans la liste de sélection affichée sur le modèle principal.
Le champ Modèle de style permet de sélectionner le modèle de style associé, afin de synchroniser les styles.
Le champ Formats disponibles permet de sélectionner un ou plusieurs formats de sortie, comme Word, PDF, etc.
Le champ Séparateur de champ pour le format CSV permet de sélectionner un séparateur.
Le champ Délimiteur de chaîne de caractères pour le format CSV permet de sélectionner le caractère englobeur pour une cellule en texte.
Le champ Types de contenu autorisés permet de sélectionner les types sur lesquels les liens de génération vont être affichés. Si aucune valeur n’est sélectionnée, le modèle est disponible pour n’importe quel type de contenu.
Le champ Modèles à fusionner permet de sélectionner un ou plusieurs sous modèles parmi ceux définis. En plus de sélectionner dans une liste déroulante un des sous modèles, on peut ajouter le nom de variable de ce modèle ainsi qu’une option de pré-rendu. Il est conseillé d’utiliser à travers tous les modèles le même nom de variable pour le même type de sous modèle. Par exemple doc_entete pour tous les sous modèle d’entête. Le pré-rendu indique si le sous modèle doit être généré avant le document principal (en cas d’indépendance au contexte, comme le logo) ou si le sous modèle sera généré en même temps que le principal. La syntaxe à indiquer dans le modèle principal est un peu différente suivant le pré-rendu ou non. Il est préférable de travailler avec le pré-rendu à Non.
Le champ Variables du contexte permet de définir des variables qui seront disponibles dans le modèle de document. Cela peut être utile, par exemple, pour utiliser le même canevas de document, avec un test spécifique sur la variable ajoutée, qui apporterait un rendu différent.
Le champ Modèle de boucle de publipostage permet de sélectionner un modèle de ce type défini dans le site et sera utilisé si un publipostage doit être effectué. Cela nécessite de placer du code spécifique dans le canevas principal utilisé.
Le champ Modification sur les colonnes de tableaux se rapporte à la gestion de la largeur des colonnes.
Le champ Condition au format TAL permet de rajouter une condition “en code informatique” afin de tester si ce modèle doit être proposé pour génération.
Le champ Rôles qui by-passent l’expression TAL permet de sélectionner des rôles pour lesquels la condition TAL est ignorée.
Modèle de document POD pour tableau de bord#
Cet élement constitue un modèle principal qui va pouvoir être sélectionné dans l’interface utilisateur pour aboutir au document généré mais est uniquement valable dans un contexte de tableau de bord.
Ce type de contenu, par rapport au modèle de document POD, remplace le champ Types de contenus autorisés par le champ Tableaux de bord autorisés et ajoute quelques champs.
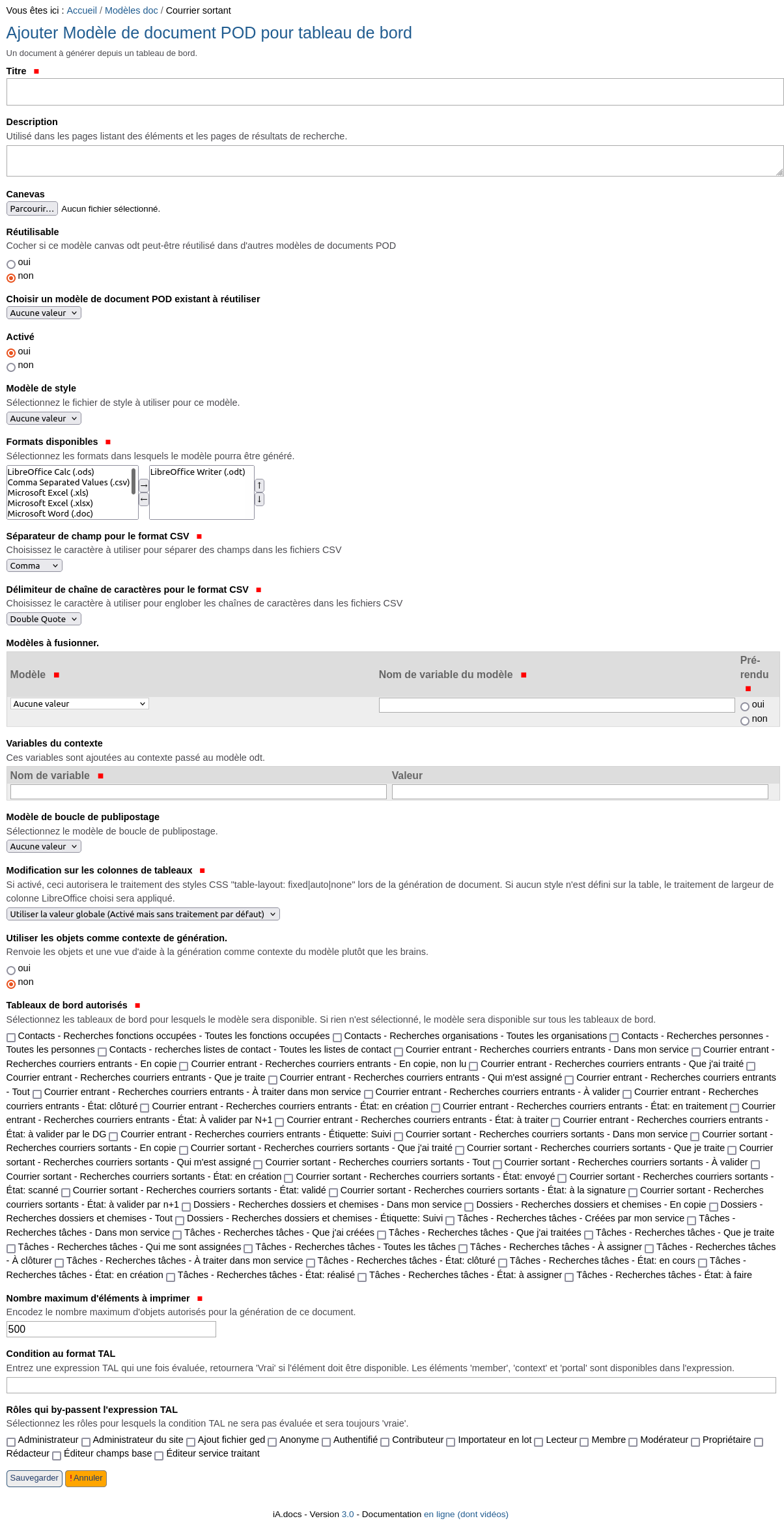
Les champs spécifiques ou complémentaires sont:
Le champ Utiliser les objets comme contexte de génération est lié au code contenu dans le canevas.
Le champ Tableaux de bord autorisés permet de sélectionner les tableaux de bord définis dans le site et sur lesquels les liens de génération pour ce modèle vont être affichés. Si aucune valeur n’est sélectionnée, le modèle est disponible pour n’importe quel tableau de bord.
Le champ Nombre maximum d’éléments à imprimer limite le nombre d’élements du tableau de bord lors de la génération.
Écriture des documents modèle LibreOffice#
Principe#
Le modèle de document bureautique est un document LibreOffice rédigé classiquement, hormis le fait non négligeable 😉 qu’il va contenir du code informatique, permettant d’afficher des données du contexte, de faire des tests, de faire des boucles, d’incorporer des sous modèles, etc.
Lors de la génération du document sur un contexte donné, le code informatique présent dans le modèle est “interprété” et remplacé par des données pour arriver à un document final.
La syntaxe informatique utilisée est celle de la libraire appy framework, dont le module pod gère la génération de document. La partie gen n’est pas utilisée.
Il est possible d’insérer le code informatique de plusieurs façons, toutes expliquées ci-dessous. La présence de ce code informatique n’empêche nullement la mise en forme.
 Le plus simple pour éditer un modèle enregistré dans Plone est
d’utiliser l’édition externe via ZopeEdit, afin de modifier
le document et, après chaque sauvegarde (sans le fermer), tester directement
la génération associée.
Le plus simple pour éditer un modèle enregistré dans Plone est
d’utiliser l’édition externe via ZopeEdit, afin de modifier
le document et, après chaque sauvegarde (sans le fermer), tester directement
la génération associée.
 La documentation ci-dessous est un résumé de la
documentation pod sus-mentionnée.
La documentation ci-dessous est un résumé de la
documentation pod sus-mentionnée.
Champ de saisie#
La première façon de réaliser la fusion de données (l’insertion d’une donnée du contexte dans le document) est d’utiliser un champ de saisie.
Pour insérer un champ dans LibreOffice, il faut positionner son curseur à l’endroit voulu et passer par le menu Insertion, ensuite Champ et enfin Autre champs… (ou CTRL+F2).
La fenêtre suivante apparait:
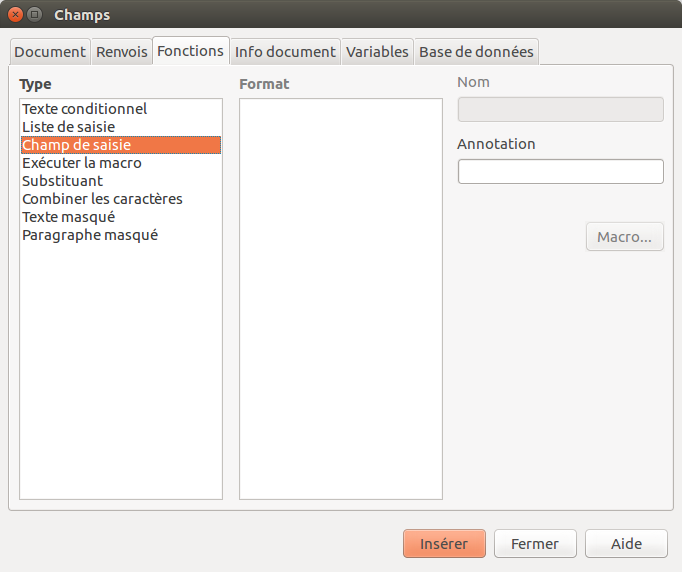
Après avoir sélectionné l’onglet Fonctions et le type Champ de saisie, il faut cliquer (une seule fois) sur Insérer. Une fenêtre supplémentaire s’affiche, permettant de mettre dans le champ le code informatique.
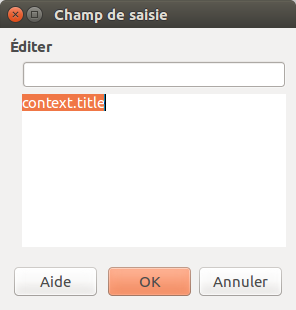
Il faut taper l’instruction dans la deuxième partie: ici comme exemple context.title qui va récupérer l’attribut title du contexte. Après avoir cliqué sur OK, le champ est inséré dans le document. Il faut alors fermer la fenêtre Champs pour revenir au document (en cliquant sur la croix ou avec la touche Esc).
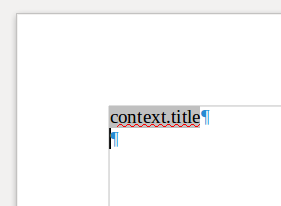
Pour modifier un champ de saisie, il faut cliquer une fois dessus, ce qui place le curseur de la souris à la fin de l’instruction.
Champ Texte conditionnel#
Ce champ a un objectif identique au champ de saisie mais ajoute une notion de condition. Si celle-ci est remplie au moment de la génération, le champ est rendu. Si la condition n’est pas remplie, le champ n’est pas rendu et est laissé dans le document, dans le but d’être rendu ultérieurement ! C’est le cas par exemple d’un champ lié au publipostage qui doit être rendu seulement après l’action de publipostage.
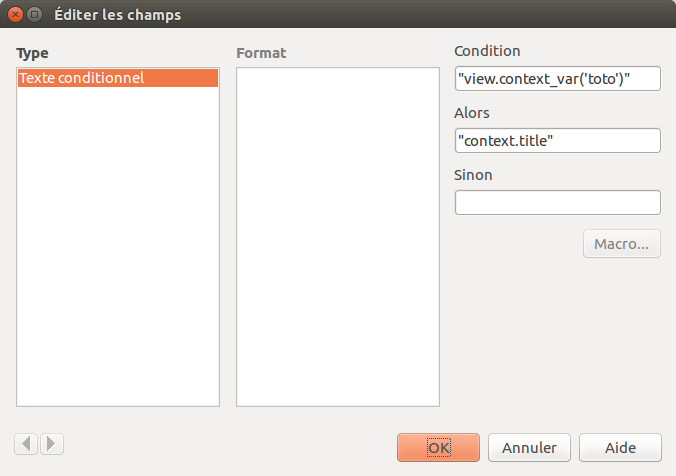
Pour insérer un champ Texte conditionnel, dans LibreOffice, il faut positionner son curseur à l’endroit voulu et passer par le menu Insertion, ensuite Champ et enfin Autre champs… (ou Ctrl+F2). Après avoir sélectionné l’onglet Fonctions et le type Texte conditionnel, il faut remplir les champs:
Condition: c’est la condition qui sera testée pour voir si le champ doit être rendu ou non.
Alors: c’est l’instruction du champ
Attention, que c’est deux champs doivent être définis comme du texte, c’est-à-dire entourés de simple ou double quote.
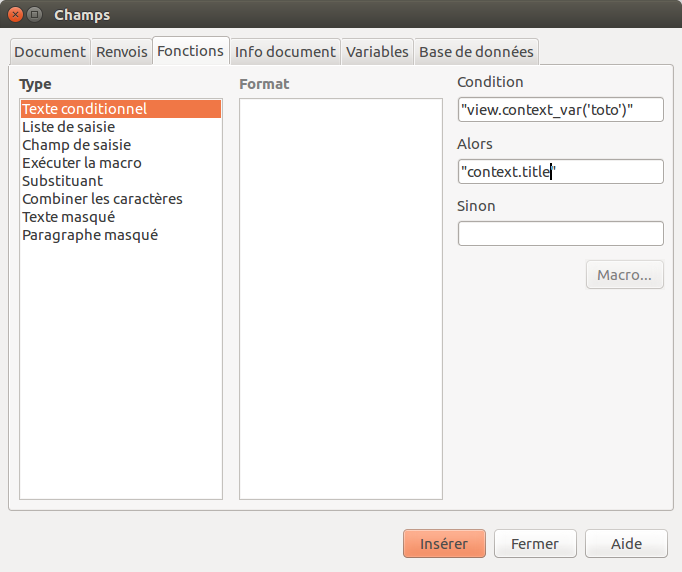
Après seulement, il faut cliquer (une seule fois) sur Insérer pour insérer ce champ. Il faut alors fermer la fenêtre Champs pour revenir au document (en cliquant sur la croix ou avec la touche Esc).
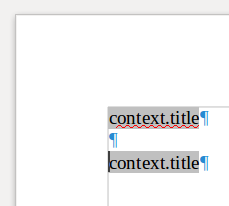
En apparence le champ Texte conditionnel ressemble au champ de saisie mais si on laisse son curseur de souris dessus pendant 2 secondes, la condition apparait sur fond noir.
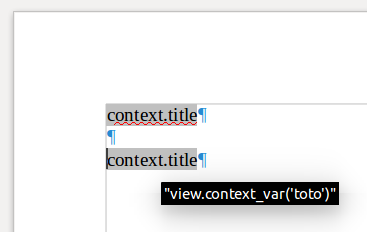
Il est possible également de distinguer plus facilement les 2 types de champs par la méthode suivante. Via le menu Affichage, cliquer sur Noms de champ ou utiliser le raccourci Ctrl+F9.
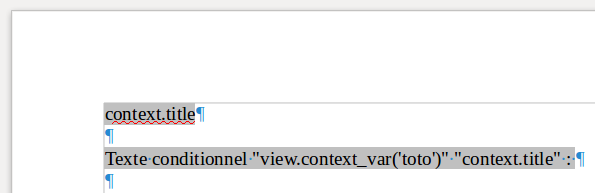
Le champ de saisie n’affiche pas d’information particulière tandis que le champ Texte conditionnel contient le type et la condition en plus.
Pour modifier un champ texte conditionnel, il faut double cliquer dessus, ce qui ouvre une fenêtre presque identique à l’insertion et permet de modifier les valeurs.
Commentaire#
Un commentaire va permettre d’introduire du code permettant de réaliser des opérations plus complexes qu’intégrer une simple valeur dans le document. Il va en effet permettre les choses suivantes:
intégrer des parties de document via les sous modèles
réaliser des tests pour conditionner le rendu d’une section, d’un paragraphe, d’un titre, d’un tableau, d’une ligne de tableau ou d’une cellule de tableau
réaliser des boucles pour répéter le rendu des mêmes types d’éléments sus-mentionnés
définir des variables pour faciliter le code informatique
Pour insérer un commentaire, dans LibreOffice, il faut positionner son curseur à l’endroit voulu et passer par le menu Insertion, ensuite Commentaire (ou Ctrl+Alt+c). Le commentaire s’affiche dans la colonne de droite et permet d’y encoder le code voulu.
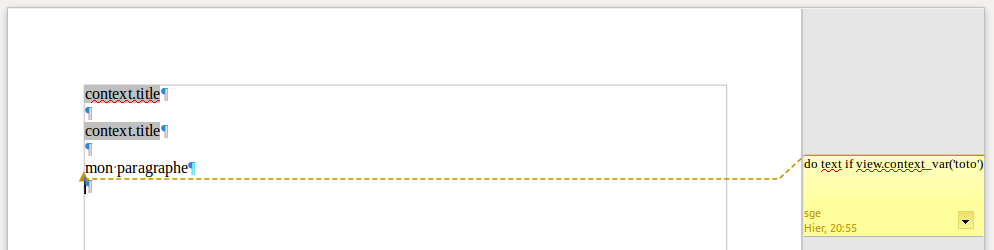
Dans notre exemple, le code signifie de rendre le paragraphe correspondant si la variable de contexte toto est définie.
Pour modifier un commentaire, il suffit de positionner son curseur à l’intérieur.
Lors de la génération à partir de ce modèle, sur le contexte de la page d’accueil d’une site standard et avec la variable “toto”, on obtient le résultat suivant:

Lors d’une génération identique mais sans la variable “toto”, on obtient le résultat:
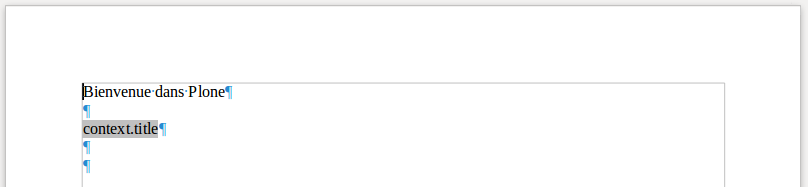
On constate que le paragraphe lié au commentaire est absent et que le champ Texte conditionnel n’a pas été rendu.
Syntaxe du code informatique#
Contexte de génération#
Lors de la génération, un ensemble de données correspondant au contexte est disponible dans le modèle. Cet ensemble de données peut varier suivant l’application.
Par défaut, les données suivantes sont disponibles:
context: il s’agit d’un objet “représentant” l’élément du site sur lequel le modèle est généré et permettant d’appeler la plupart de ses attributs (titre, description, etc.)
view: il s’agit d’un objet (vue d’aide) proposant un ensemble de méthodes (fonctions) qui peuvent être appelées
Les données définies dans le champ Variables du contexte du modèle sont également ajoutées au set disponible. Donc si le champ définit une variable toto à 1, elle sera disponible directement sous son nom au même titre que context ou view.
Dans le cas d’un modèle avec publipostage, il est nécessaire d’utiliser la variable mailed_data destinée à contenir chaque élément de la liste de publipostage renvoyée par la méthode de la vue d’aide mailing_list. Cette variable peut contenir ce que l’on veut (objet, dictionnaire).
Dans le cas d’un modèle pour tableau de bord, le modèle se génère par rapport aux éléments sélectionnés dedans. L’ensemble de données contient dès lors deux variables en plus:
brains: c’est la liste des éléments sélectionnés (sous forme d’élément du catalogue)
uids: c’est la liste des éléments sélectionnés (sous forme d’identifiant unique)
Vue d’aide (helper view)#
Il y a toujours une vue par défaut qui propose des méthodes standards utilisables. Cependant, chaque application étend les méthodes de base avec des méthodes plus spécifiques à l’application et au contexte lié.
La vue de base propose les attributs suivants:
real_context: il s’agit de l’objet du site sur lequel le modèle est généré
portal: il s’agit de l’objet “site plone”
La vue de base propose les méthodes suivantes:
get_value: renvoie la valeur stockée du champ correspondant au nom passé en paramètre
display: rend un champ (dont le nom est passé en paramètre), de manière plus “intelligente” que “get_value”
display_date: rend un champ ou une date passée en paramètre
display_list: rend un champ de type liste sous forme d’une seule chaîne de caractère
display_voc: rend un champ de type vocabulaire sous forme d’une seule chaîne de caractère
display_text_as_html: renvoie la conversion d’un champ texte en html
display_html_as_text: renvoie la conversion d’un champ html (texte riche) en champ texte brut
display_widget: rend un champ au format html, tel qu’il est rendu dans le navigateur
translate: renvoie la traduction d’une chaîne de caractère prévue dans une autre langue
get_state: renvoie l’état du contexte
context_var: teste si une variable existe dans l’ensemble de données disponibles du document et renvoie sa valeur le cas échéant
getDGHV: renvoie la vue d’aide d’un autre contexte passé en paramètre
mailing_list: renvoie la liste des éléments de publipostage (par exemple les destinataires d’un courrier)
Syntaxe appy.pod#
Il s’agit ici de la syntaxe particulière reconnue par le module appy.pod qui effectue la transformation du code informatique du modèle en contenu LibreOffice.
La documentation ci-dessous n’est peut-être plus à jour… par rapport
au module pod qui a évolué.
Définissons d’abord quelques éléments#
<python_expression> : il s’agit d’une expression python standard qui retourne une valeur. Elle peut utiliser les variables présentes dans le contexte de génération.
<document_part> : il s’agit d’un élément représentant une partie du document. Les valeurs possibles (pour un modèle odt) sont:
text: pour un paragraphe
title: pour un titre
section: pour une section
table: pour un tableau
row: pour une ligne de tableau
cell: pour une cellule de tableau
<label:> : il s’agit d’un libellé qui peut être indiqué au début d’une expression appy. Il se termine par “:”. Le libellé peut être alpha-numérique et contenir aussi le caractère “_”.
Expressions reconnues par appy#
Dans un champ, il suffit simplement d’y placer une expression python, tel que définie ci-dessus.
Les commentaires acceptent une syntaxe plus particulière pour effectuer des opérations un peu plus complexes. Ce qui est indiqué entre crochets, dans la syntaxe des expressions, est optionnel.
[<label:>] do <document_part> if <python_expression> : inclut la partie de document référencée si la condition est remplie
do <document_part> else [<label>] : inclut la partie de document référencée, si la dernière condition utilisée dans un commentaire précédent n’est pas remplie. Afin de lier clairement la commande “else” avec le “if” correspondant, il est recommandé d’utiliser un libellé sur le “if” et d’y faire référence après “else”. Par exemple: titi: do text if titi==‘gentil’ et do text else titi
do <document_part> with <python_expression> : définit des variables dans l’expression python, séparées par le caractère “;” s’il y en a plusieurs. Les variables peuvent être séparées par des espaces. Pas de “;” à la fin ! Exemple: do text with titi=‘gentil’; grosminet=‘méchant’ .
do <document_part> for <variable_name>[, <variable_name>] in <python_expression> : répète la partie de document référencée pour chaque valeur de la liste retournée par l’expression python. À chaque itération, la valeur est stockée dans le nom de variable indiqué.
do <document_part> from <python_expression> : remplace la partie de document par la valeur retournée par l’expression python, qui doit être du code xml compatible avec le format LibreOffice. Le mot “from” doit être mis à la ligne ! L’expression python va en général utiliser une fonction appy.pod (voir ci-dessous).
do <document_part> meta-if <python_expression> : il s’agit de la correspondance du champ Texte conditionnel mais pour un commentaire. Si la condition est remplie le commentaire est interprété et remplacé. Si la condition n’est pas remplie, le commentaire est laissé tel quel dans le document et nécessitera un deuxième passage pour le remplacer, c’est-à-dire une nouvelle génération en prenant le premier document généré comme modèle.
Combinaison des expressions#
Il est possible de combiner les expressions appy. Il faut considérer que les expressions sont interprétées les unes après les autres (du haut vers le bas). Il est nécessaire de les séparer par un passage à la ligne.
Par exemple, le code suivant permet de boucler sur une liste de personne présentes dans une liste de groupes, sous la condition que le nom des personnes commence par P ou R.
do text with groups = view.getGroups()
for group in groups
with persons = group.persons
for p in persons
if p.name.startswith('P') or p.name.startswith('R')
Fonctions proposées par appy.pod#
xhtml : cette fonction transforme de l’xhtml (un champ texte riche) par de l’xml LibreOffice. Elle est donc à utiliser avec l’expression do … from xhtml(…)
document : cette fonction permet d’inclure un autre document LibreOffice ou une image. Elle peut donc être utilisée pour intégrer un sous modèle. Elle est à utiliser avec l’expression do … from document(…)
pod : cette fonction permet d’inclure le rendu d’un autre modèle. Elle peut donc être utilisée pour intégrer un sous modèle. Elle est à utiliser avec l’expression do … from pod(…)
Erreurs de syntaxe courantes#
Un commentaire contenant une partie de document référencée doit évidemment se trouver dans ce type d’élément. Par exemple, mettre un commentaire do table en dehors d’un tableau provoquera une erreur !
Il faut utiliser pour les chaines de caractères un vrai quote ’ ou double quote « . Attention à ce que LibreOffice ne les remplace pas par des caractères plus jolis comme ‘ ’ “ ”. Si c’est le cas, il faut soit annuler globalement ce remplacement dans la configuration, soit faire un Ctrl+z juste après avoir tapé le caractère.
Les expressions python et appy.pod sont sensibles à la casse. Attention à ce que LibreOffice ne les remplace pas en début de phrase par exemple. Si c’est le cas, il faut faire un Ctrl+z juste après avoir tapé le caractère.
Lors de l’insertion des champs, il arrive de cliquer plusieurs fois sur le bouton Insérer ce qui peut insérer un champ vide. Dans ce cas, la génération se plante. Il est dans ce cas intéressant de double cliquer sur le premier champ (une fois pour un champ de saisie et une fois pour un champ Texte conditionnel) et d’utiliser les flèches en bas à gauche pour se déplacer d’un champ à l’autre afin de vérifier s’ils sont bien tous remplis. En cas de champ vide, il faut sortir de la fenêtre Champs et l’effacer dans le document.
Si une erreur se produit lors de l’interprétation d’un commentaire, l’erreur est affichée dans un commentaire dans le document généré.